ナベアツは数字がでかくなるほどアホになる割合がアップすると聞いたので検証してみました https://twitter.com/jagarikin/status/1711855799184785732
これをRでやってみるべく、MITTIさんが書いたコードが重いらしいです。
f <- function(n){ x <- 1:10^n mean(str_detect(x, "[3]") | x %% 3 == 0) }f(8)でmacがフリーズして困ったことになってる😇
というわけで高速化してみましょう。
3の倍数を速く見つける
一般的な方法として3の倍数かどうかを判定するには3で割った余りが0であるか確認するのが良いです。
しかし、桁が増えると計算負荷が高くなるのも当然です。
今回の場合、1:10^nに対してそれぞれが3の倍数か判定しているところに注目すると、剰余の計算が不要になります。
だって3の倍数は3回ごとに現れるのだもの。
n <- 7
bench::mark(
occurrence = rep_len(c(FALSE, FALSE, TRUE), 10L^n),
jouyo = seq(10L^n) %% 3L == 0L,
min_iterations = 10
) |> plot()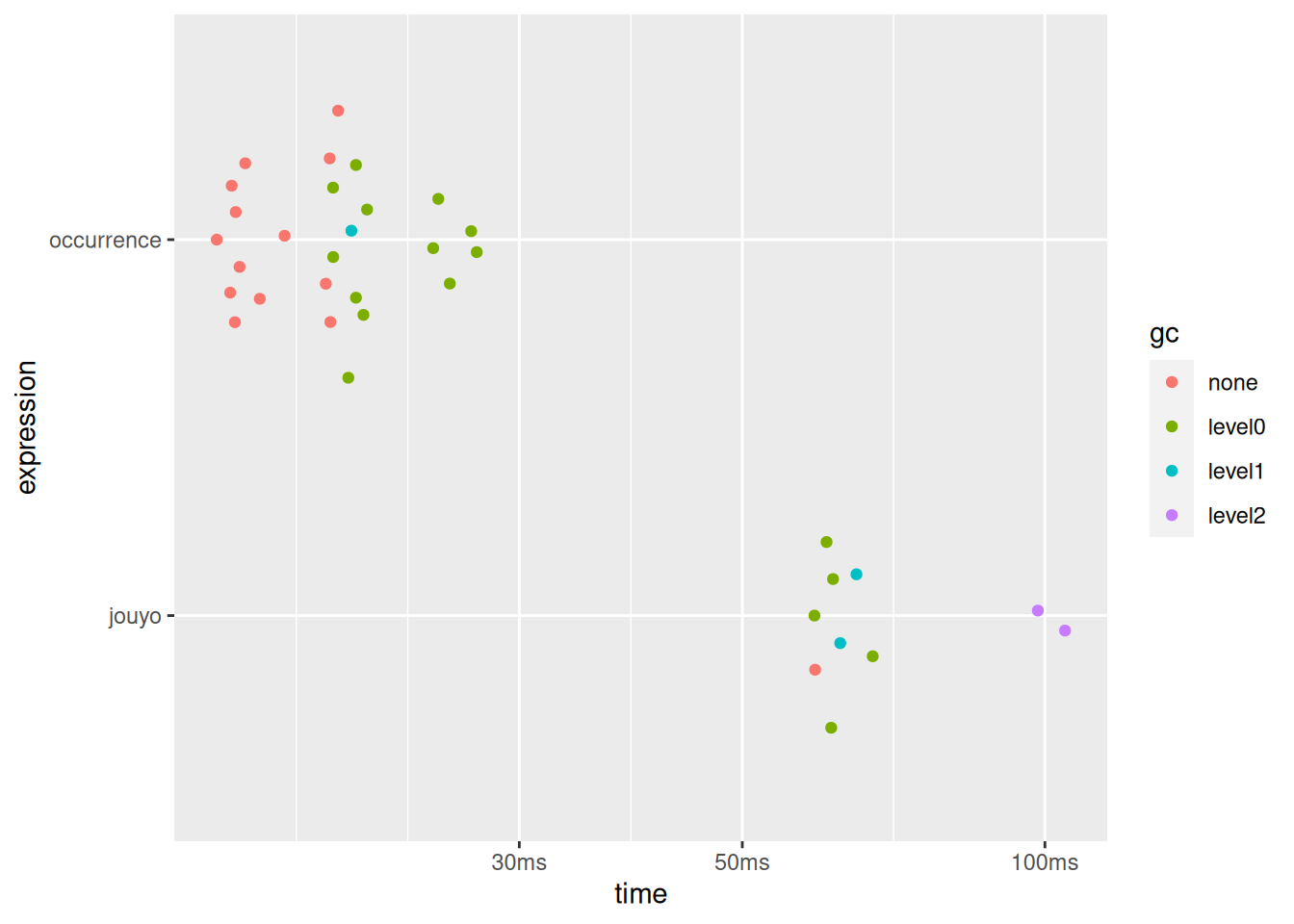
3のつく数を速く見つける
元の例では str_detect(x, "[3]") と、正規表現を使って検出しています。しかし、今回は正規表現まで使う理由は薄いですね。
stringi::stri_detect_fixed() や grepl(fixed = TRUE) を使うと良いでしょう。なぜかは知りませんが、部分一致であればgrepl(fixed = TRUE)が最速のようです。
baseパッケージもあなどれませんね。
x <- seq(10^6)
bench::mark(
stri_detect_fixed = stringi::stri_detect_fixed(x, "3"),
str_detect = stringr::str_detect(x, "3"),
grepl_fixed = grepl("3", x, fixed = TRUE),
grepl = grepl("3", x),
min_iterations = 10
) |> plot()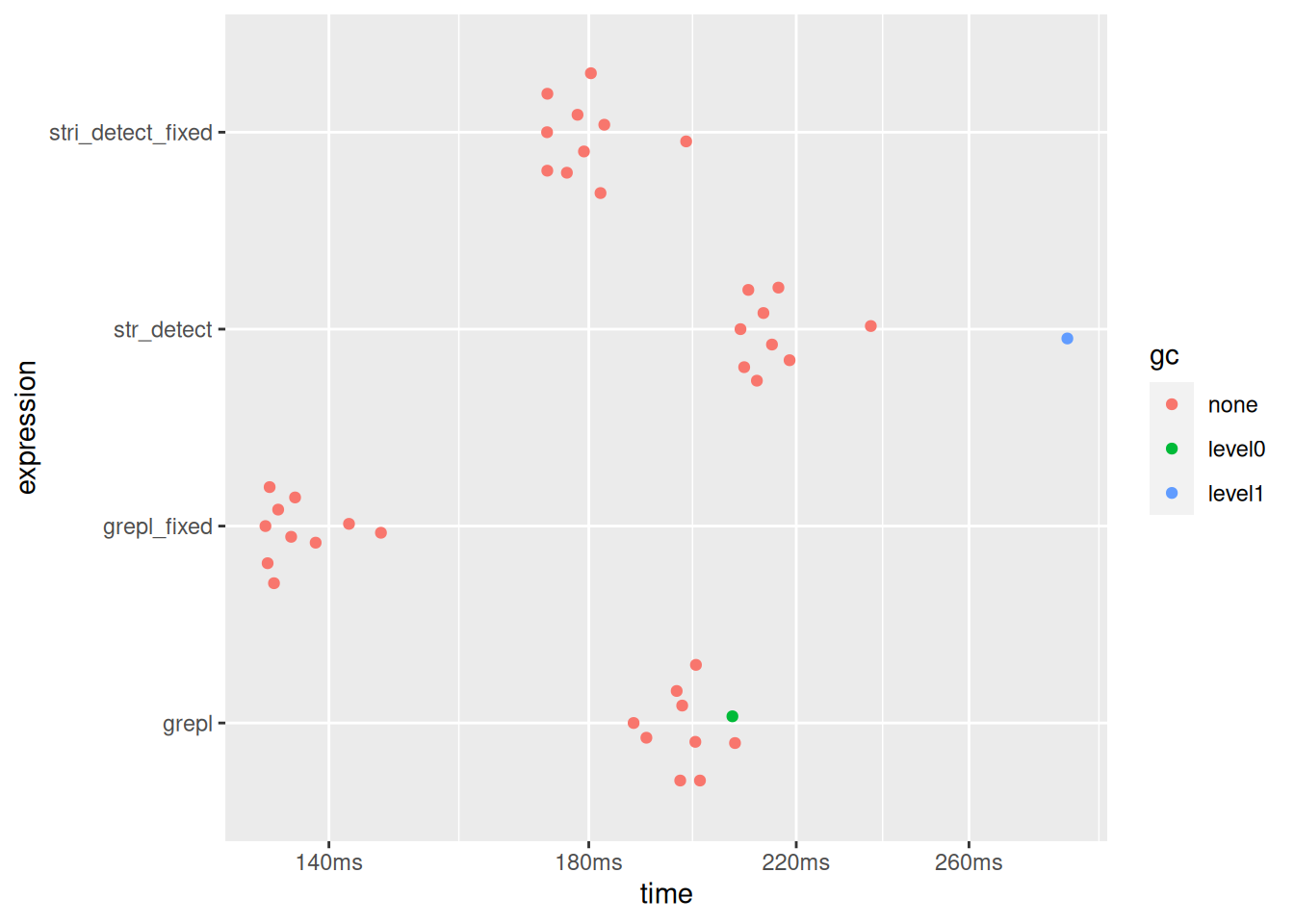
ところで、任意の数値に対して3を含むか検証するのであれば上記が一般解でしょう。
3の倍数の検出でも指摘した通り、今回は1:10^nという数列に対して3を含むか検出したいので、3がどこに現れるか考えると、ずっと速くなります。
たとえば1の位に3が出現するのは3, 13, 23, … と10回起きです。 10の位に3が出現するのは30~39, 130~139, 230~239, …と100回起きに10回です。
この性質に注目したhas3_by_occurrence()を、先のgrepl(fixed = TRUE)と比較してみましょう。
has3_internal <- function(n) {
x <- rep_len(FALSE, 10L^n)
k <- 10L^(n - 1L)
i <- 3L * k
x[i:(i + k - 1)] <- TRUE
x
}
has3_by_occurrence <- function(n) {
len <- 10^n
x <- logical(len)
for (i in seq(n)) {
x[rep_len(has3_internal(i), len)] <- TRUE
}
x
}
bench::mark(
occurrence = has3_by_occurrence(7),
grepl_fixed = grepl("3", seq(10^7), fixed = TRUE),
min_iterations = 10,
) |> plot()
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.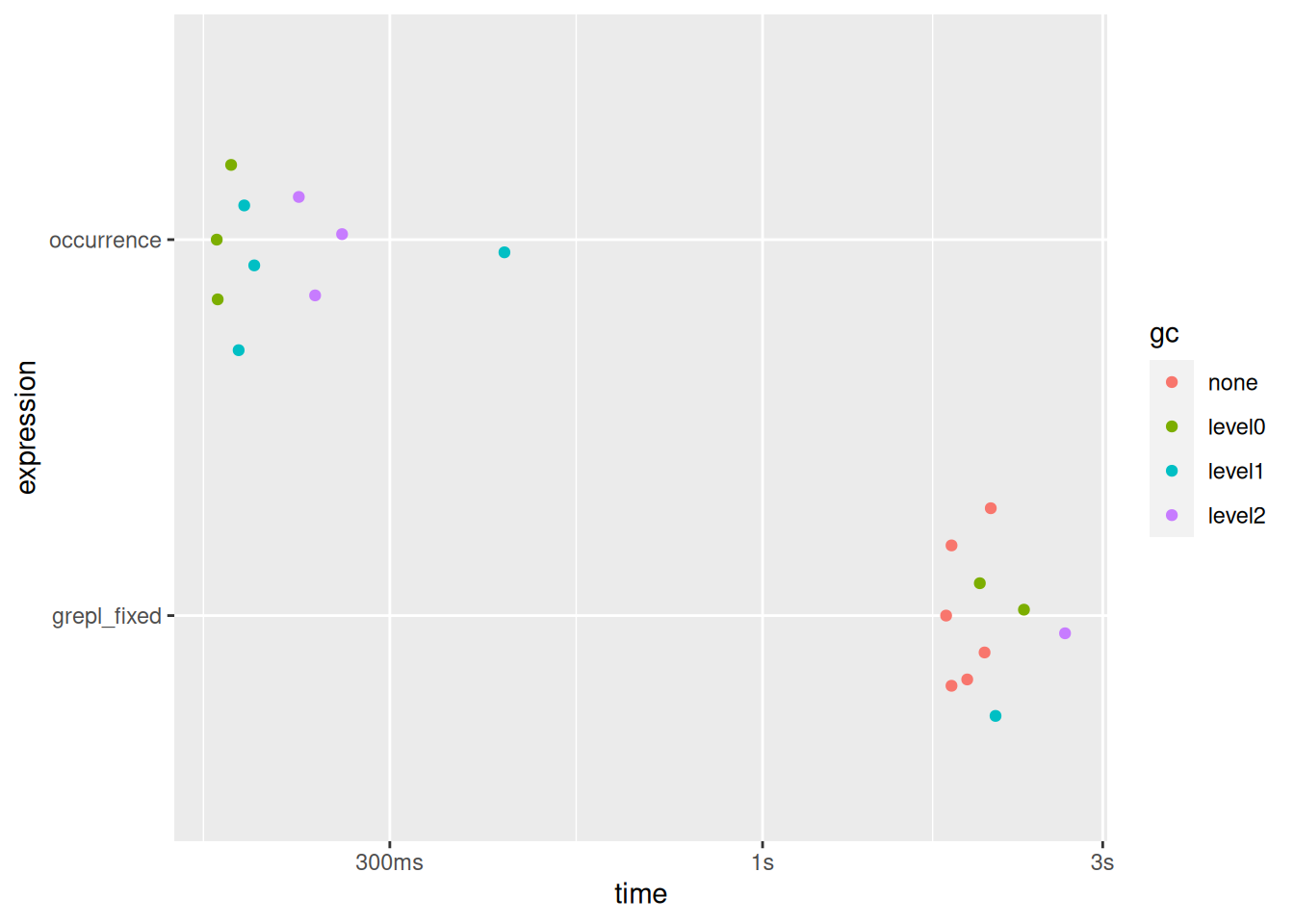
ケタで速いですね。
ちなみに、has3_by_occurrence()では、has3_internal()の返り値をrep_len()して長さ調整していました。
可読性を犠牲にしていいならば、Rがベクトルをリサイクルする仕組みを利用すると、更に速くなります。
has3_by_occurrence2 <- function(n) {
len <- 10^n
x <- logical(len)
for (i in seq(n)) {
x[has3_internal(i)] <- TRUE
}
x
}
bench::mark(
occurrence1 = has3_by_occurrence(7),
occurrence2 = has3_by_occurrence2(7),
min_iterations = 10,
) |> plot()
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.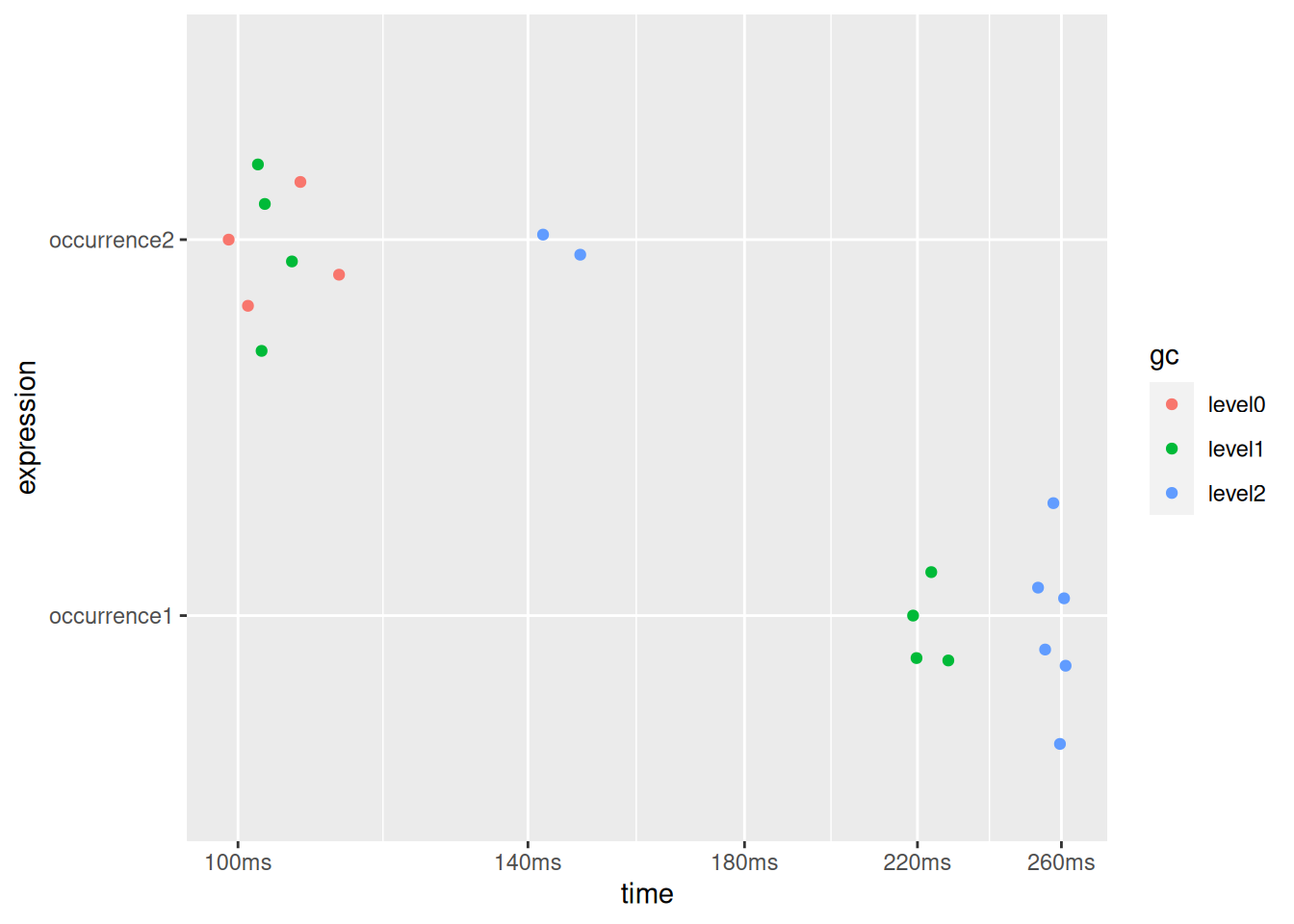
3の倍数または3のつく数を速く見つける
以上を踏まえて、元の例をbaselineとしたベンチマークを比較してみましょう。
aho_baseline <- function(n) {
x <- 1:10^n
stringr::str_detect(x, "[3]") | x %% 3 == 0
}
aho_fast_internal <- function(n) {
x <- rep_len(FALSE, 10L^n)
k <- 10L^(n - 1L)
i <- 3L * k
x[i:(i + k - 1)] <- TRUE
x
}
aho_fast <- function(n) {
len <- 10L^n
# 3の倍数ならTRUE
x <- rep_len(c(FALSE, FALSE, TRUE), len) # 3の倍数でバカになる
# 3がつくならTRUE
for (m in seq(n)) {
x[aho_fast_internal(m)] <- TRUE # 3がつくとバカになる
}
x
}
bench::mark(
baseline = aho_baseline(6),
fast = aho_fast(6),
min_iterations = 10,
) |> plot()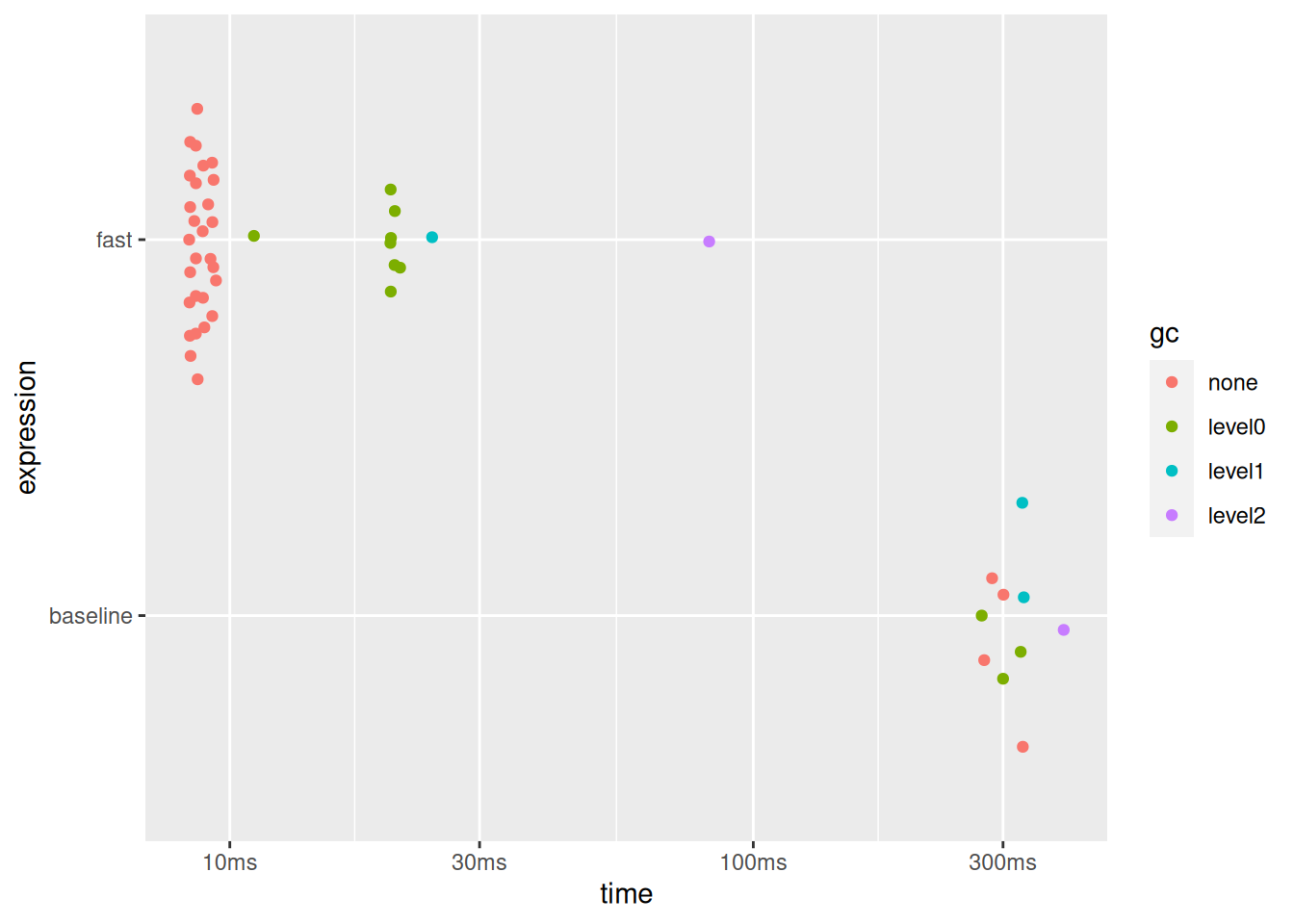
十分に高速化していますね。ちょっと意外かもしれませんが、ここでは for が高速化で大活躍しています。
MITTIさんとは環境が異なるものの、8ケタでも十分に戦えます。
plot(bench::mark(aho_fast(8), min_iterations = 10))
#> Warning: Some expressions had a GC in every iteration; so filtering is
#> disabled.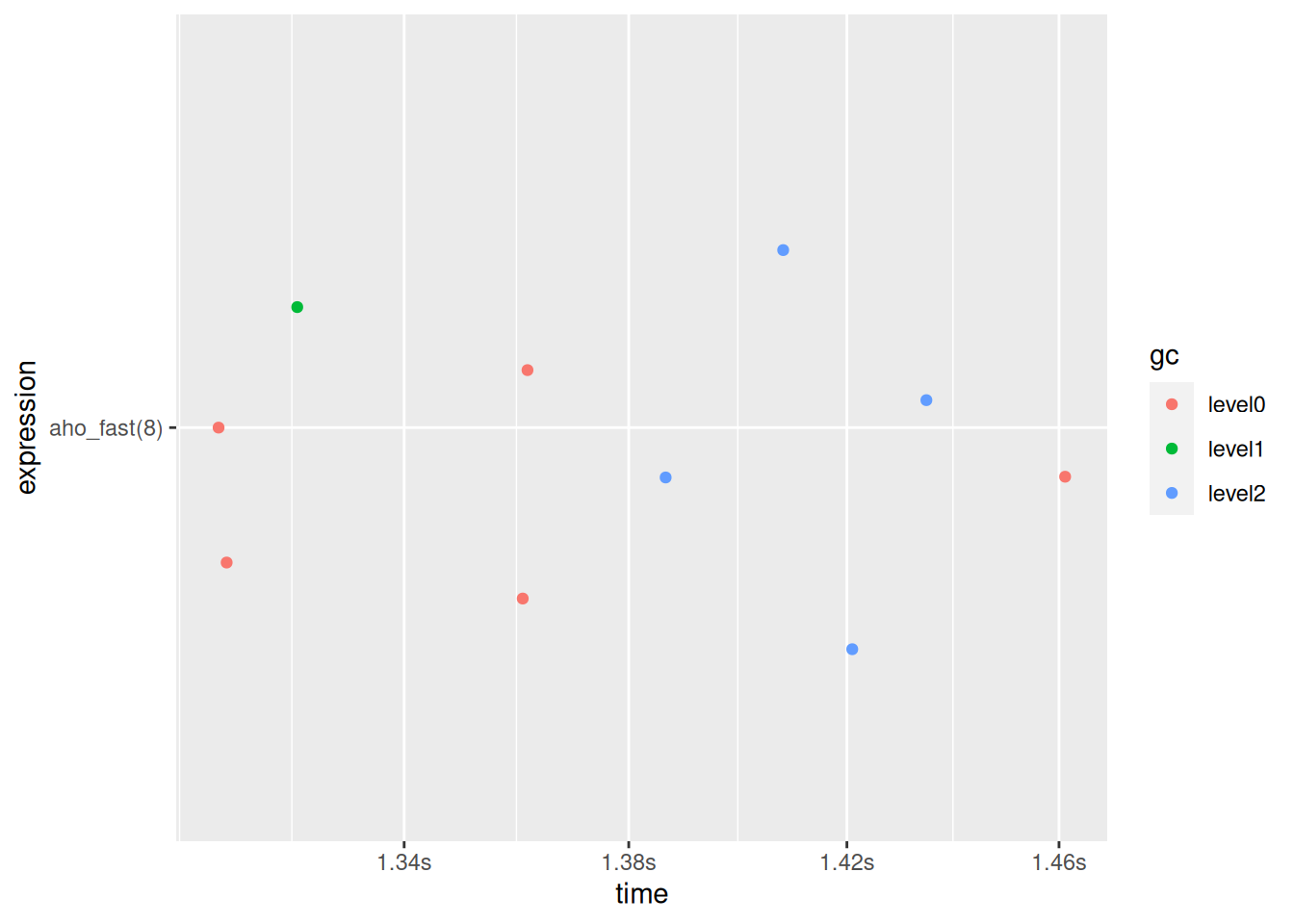
アホになる割合
せっかくなので見ておきましょう。
seq(8) |>
purrr::map_dbl(function(n) mean(aho_fast(n))) |>
print() |>
plot()
#> [1] 0.3000000 0.4500000 0.5130000 0.5625000 0.6063300 0.6457050 0.6811353
#> [8] 0.7130218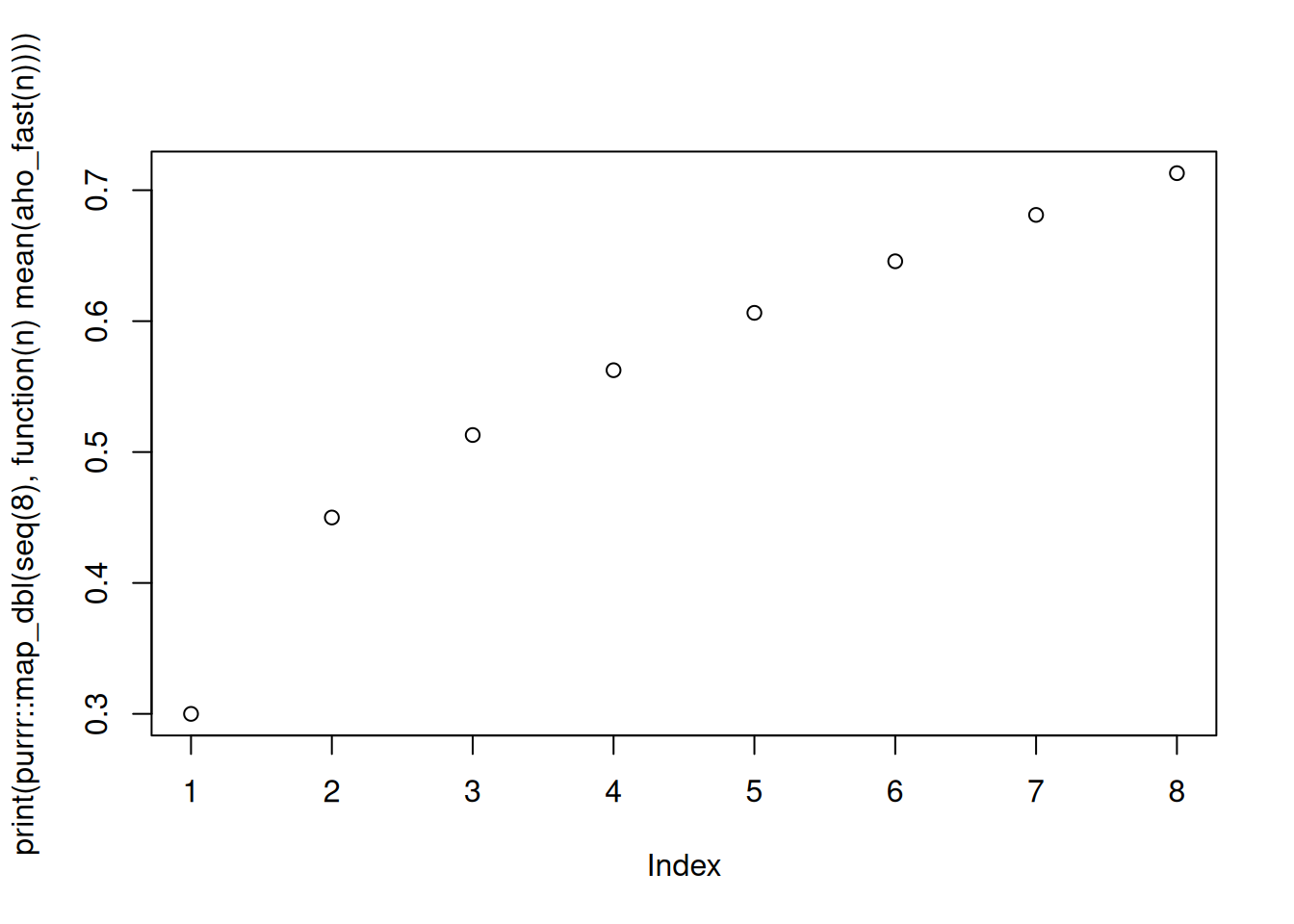
あまり知られていないかもしれませんが、Rにおいて、print関数は入力をそのまま返すのがお作法とされています。なのでパイプの間に挟んでもちゃんと機能します。
いやあ、こういうRらしさを使った高速化、楽しいですね!
ENJOY!