dplyr::mutate_all はデータフレーム中の各変数 (列) に対して関数を適用する。
purrr::modify はリストライクなオブジェクトの各要素に対して関数を適用するが、返り値は入力したオブジェクトと同じクラスになる。このため、データフレームを入力するとデータフレームを返すので、 dplyr::mutate_all のように振る舞うことができる。
purrr::modify の方が色々なデータを受け取れる上位互換なのだろうか? と疑問に思ったので調べてみた。
引数を比べてみる
library(dplyr)
library(purrr)args(dplyr::mutate_all)
#> function (.tbl, .funs, ...)
#> NULL
args(purrr::modify)
#> function (.x, .f, ...)
#> NULLさっそく違いが分かるが、mutate_all の第二引数は funs で複数の関数を取る。つまり複数の関数をデータフレームに適用できる。一方で modify の第二引数は .f で一つの関数しか取れない。
なお、Ellipsis (...) には、 .funs や .f に追加で指定したい引数を与えることができる。
mutate_all を使ってみる
シンプルなデータフレームを容易しておこう。
d <- data.frame(x = 1:3, y = 4:6).funs に単一の関数として sqrt を指定すると、x と y の平方根が得られる。
d %>% mutate_all(sqrt)
#> x y
#> 1 1.000000 2.000000
#> 2 1.414214 2.236068
#> 3 1.732051 2.449490一方、.funs = list(sqrt, log) として複数の関数を指定すると、x 列、 y 列はそのままに、関数を適用した結果の列が x_fn1, y_fn1, x_fn2, y_fn2 といった具合に追加される。
d %>% mutate_all(list(sqrt, log))
#> x y x_fn1 y_fn1 x_fn2 y_fn2
#> 1 1 4 1.000000 2.000000 0.0000000 1.386294
#> 2 2 5 1.414214 2.236068 0.6931472 1.609438
#> 3 3 6 1.732051 2.449490 1.0986123 1.791759_fn* というサフィックスをコントロールしたい場合は、 .funs に与える関数のリストを名前付きリストにしておけばいい。
d %>% mutate_all(list(sqrt = sqrt, log = log))
#> x y x_sqrt y_sqrt x_log y_log
#> 1 1 4 1.000000 2.000000 0.0000000 1.386294
#> 2 2 5 1.414214 2.236068 0.6931472 1.609438
#> 3 3 6 1.732051 2.449490 1.0986123 1.791759modify を使ってみる
d %>% modify(sqrt)
#> x y
#> 1 1.000000 2.000000
#> 2 1.414214 2.236068
#> 3 1.732051 2.449490d %>% mutate_all(sqrt) と同じ結果が得られた。
ベンチマーク
適用する関数が一つだけの時は mutate_all と modify は同じ結果を返すので、それぞれの性能を比較してみることにした。
library(bench)
library(ggplot2)autoplot(mark(
mutate_all(d, identity),
modify(d, identity)
))
#> Loading required namespace: tidyr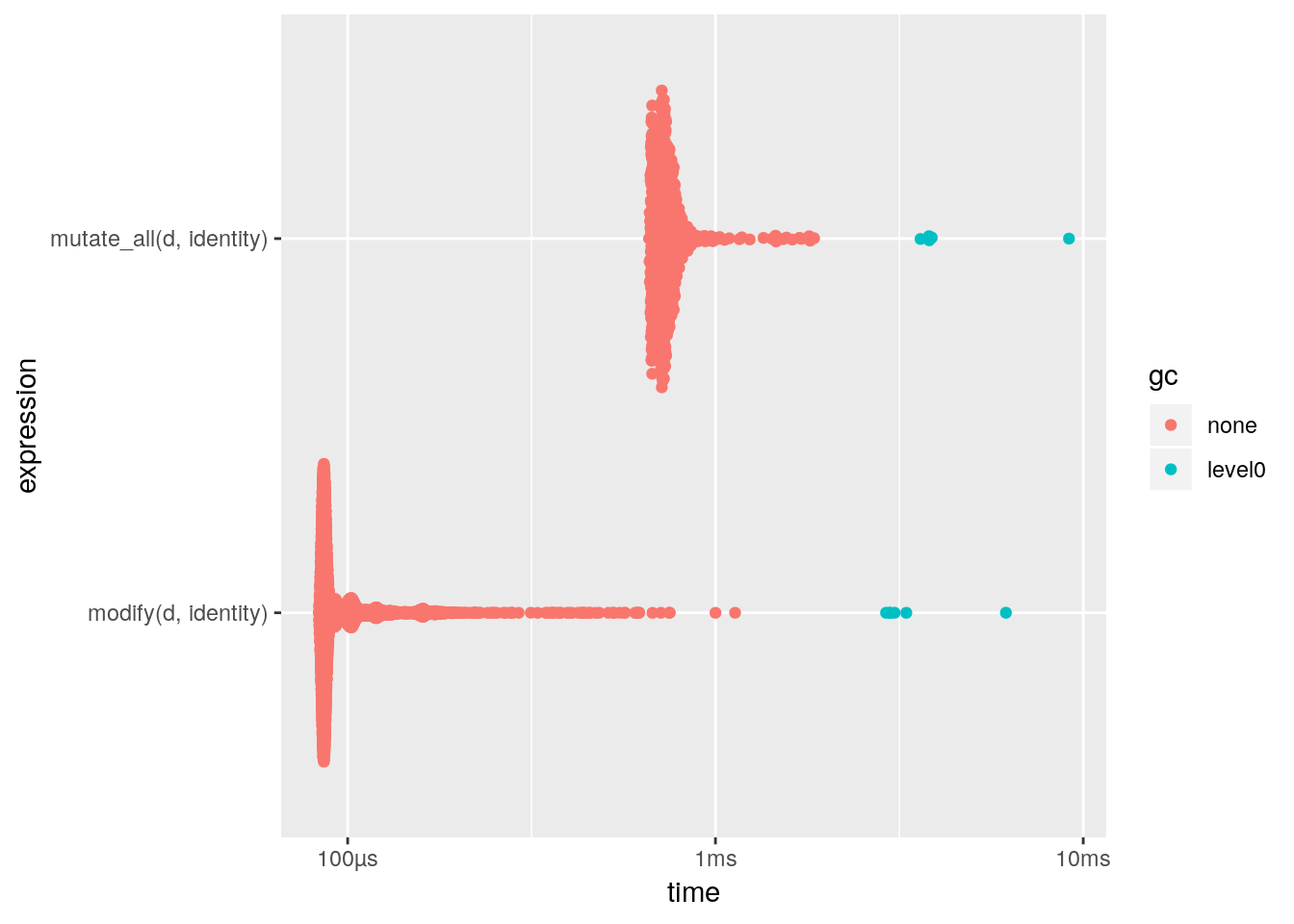
機能がシンプルな分 modify が圧倒的ですね。